Fine-tune Transformers Faster with Lightning Flash and Torch ORT
Torch ORT uses the ONNX Runtime to improve training and inference times for PyTorch models.
With Lightning Flash, all it takes is enable_ort=Trueto use Torch ORT when training Transformer based models, giving you the power to use all features Lightning provides, such as Callbacks, Logging, Mixed Precision, and Distributed Training with support for Advanced Distributed Plugins.
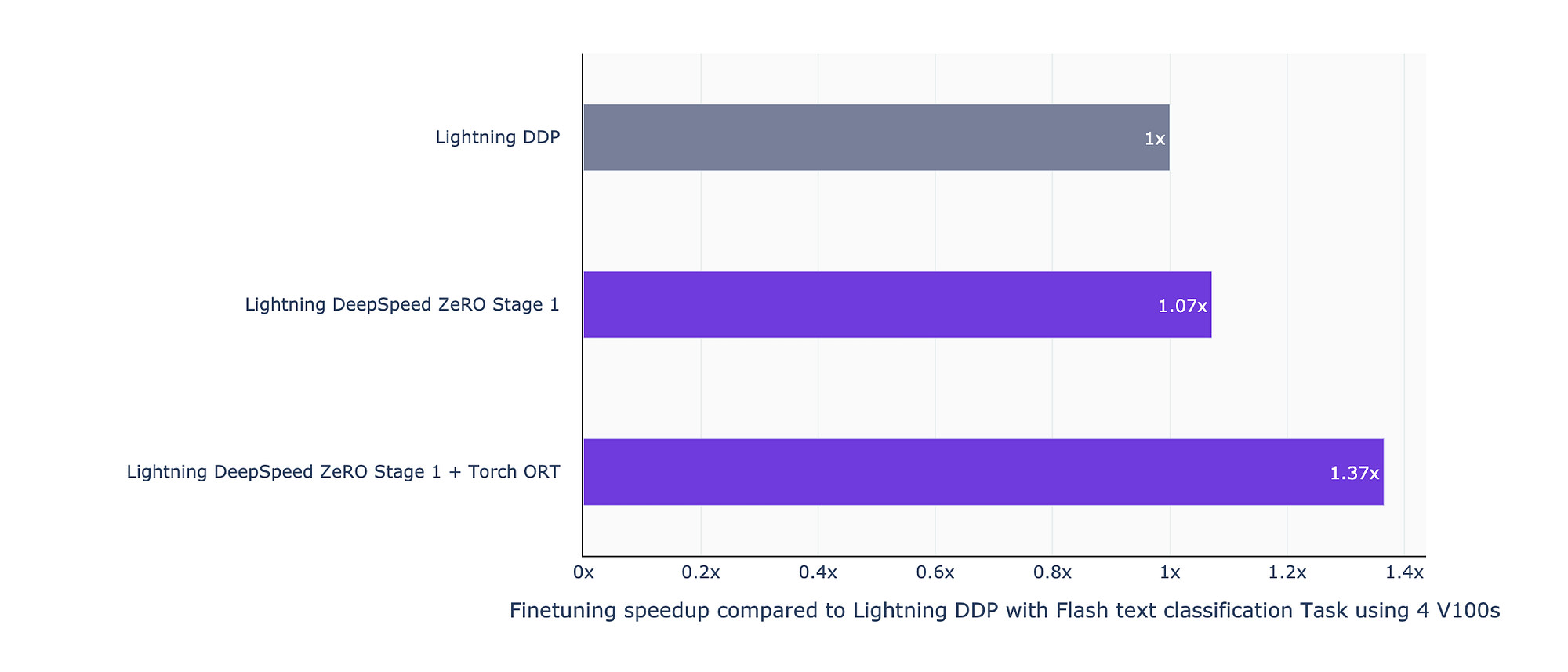
Below we describe how you can use Lightning Flash with Torch ORT training a Transformer model with the Flash Text Classification Task and see impressive speedups!

In line with PyTorch Lightning’s goal of getting rid of the boilerplate, Flash aims to make it easy to train, inference, and fine-tune deep learning models.
Flash is built on top of PyTorch Lightning to abstract away the unnecessary boilerplate for common Deep Learning Tasks.
Since Flash is built on top of PyTorch Lightning, as you learn more, you can override your Task code seamlessly with both Lightning and PyTorch to find the right level of abstraction for your scenario.
Fine-tuning Transformers using Lightning Flash and Torch ORT
Below we walk through the two steps required to fine-tune a Transformers text classification task using Torch ORT.
Step 1: Load your Data
First, let’s install lightning-flash from master and import the libraries to use the Speech Recognition Task.
Make sure to install Torch ORT, which requires certain CUDA versions to be installed (or optionally use Docker). Instructions here!
Now that we have installed flash and loaded our dependencies, let’s talk about data. To fine-tune our first Text Classification model, we will be using the IMDB dataset as an example, curated with labeled reviews paired with positive or negative sentiment scores.
The dataset contains reviews and an associated sentiment of positive or negative. Here is a piece of the CSV file.
review,sentiment
"... Running makes them all feel truly alive. The big life-altering running adventure comes to an end when they accidentally get in the middle of something big, violent, and so absurd that it's funny in a clever way. One of my favorite films of all time by genius director Sabu.",positive
"This is borne out with Special Forces and Undisputed 2, but unfortunately The Shepherd just doesn't live up to their abilities.<br /><br />There is no doubt that JCVD looks better here fight-wise than he has done in years, especially in the fight he has (for pretty much no reason) ...",negativeThe first thing we need to do is download the dataset using the following code.
Once we have downloaded the IMDB dataset, Flash provides a TextClassificationData module that handles the complexity of loading the Text data from the CSV file and converting it into a representation that Deep Learning models need to train.
Step 2: Fine-tune the Text Classification Task using Torch ORT
Once we have loaded our dataset, we need to select the backbone for our task to fine-tune and enable torch ORT.
We select BART-large, a supported backbone by torch ORT. See this table for more torch ORT approved backbones.
In the Flash, to enable Torch ORT and select your backbone is extremely simple. Simply pass the enable_ort=True flag and set backbone='facebook/bart-large' it using the TextClassifier Task.
Now that we have chosen the model and loaded our data, it’s time to train the model on our classification task using the following two lines of code:
With multiple GPUS, enabling the advanced distributed plugin DeepSpeed Stage 1, can further improve performance. DeepSpeed Stage 1 comes with optimized distributed communications across GPUs + some memory benefits from sharding your optimizer states! More information can be read in our Model Parallel documentation.
The Flash Trainer is built on top of PyTorch Lightning, meaning it is seamless to distribute training onto multiple GPUs, Cluster Nodes, and even TPUs.
Putting it All Together
The steps above are condensed into the code below, demonstrating how easy it is to fine-tune your own Text Classification model using Torch ORT!
Next Steps
For more information about Torch ORT and Lightning Flash, dive into our documentation, as well as the torch ORT repository for more use cases!
Also, check out the early access distributed training features in Grid that enable you to scale your Flash transformer models without worrying about infrastructure.

Grid.AI enables you to scale training from your laptop to the cloud without having to modify a single line of code. While Grid supports all the classic Machine Learning Frameworks such as TensorFlow, Keras, PyTorch and more. Leveraging Lightning features such as Early Stopping, Integrated Logging, Automatic Checkpointing, and CLI enables you to make the traditional MLOps behind model training seem invisible.
About The Author
Sean Narenthiran is a research engineer within the Grid AI Labs and PyTorch Lightning. Sean has worked in machine learning extensively to improve, innovate, and scale deep learning approaches for voice analytics and natural language processing, particularly in the financial domain. Sean also maintains and contributes to a variety of open-source PyTorch projects, such as DeepSpeech, PyTorch, NeMo, and more.

