Lightning Flash now supports Meta-Learning!

Lightning Flash is a PyTorch AI Factory built on top of PyTorch Lightning. Flash helps you quickly develop strong baselines on your data with over 15+ tasks and 7 data domains.
For more information about Lightning Flash, dive into our documentation to take a look at our new examples!
We recently added meta-learning algorithms support for Flash ImageClassification Tasks including:
- Integration with 4 meta-learning algorithms backed by the Learn2Learn framework:
maml,anil,metaoptnetandprototypicalnetworks. - The Flash integration brings
ddpsupport to Learn2Learn providing a significant speed-up compared to their originaldpimplementation.
After completing this tutorial, you will know how to leverage meta-learning for image classification with Flash.
Find the full example here.
What is Meta-Learning and why should you care?
Humans are able to distinguish between new objects with little or no training data. However, machine learning models often require thousands, millions, billions of annotated data samples to achieve good performance while extrapolating their learned knowledge on unseen objects.
A machine learning model which can learn or learn to learn from only a few new samples would have tremendous applications once deployed in production. This process is called few-shot learning. The extreme cases of few-shot learning such as one-shot or zero-shot learning provide even more advantages for users.
Meta-learning has recently enabled rapid and exciting progress in few-shot learning algorithms. This is often characterized as teaching deep learning models to learn with only a few labeled data.
The goal of Meta-Learning is to learn from few-shot examples that during training match the structure of the final k-shots used in production. It is important to note that the few-shot examples seen in production contain unseen objects.
How does Meta-Learning work?
A few-shot episode is the smallest unit of data and it represents the data available to the model once in its deployment environment. In meta-learning, a model is trained over multiple few-shot episodes. By doing so, we can optimize the model and get higher results once deployed.
A few-shot episode consists of a support set (for adapting the model to the episode) and a query set (for evaluating the generality of the adapted model).
In a few-shot episode for image classification, the number of samples in the support set are called the shots of the episode and the number of classes the ways; so, a 2-ways 2-shots 1query episode contains 2 classes, each with a two data sample in the support set and one data sample in the query set. The query set would contain the same structure, but classes not present within the support set.
Here is an example in image.
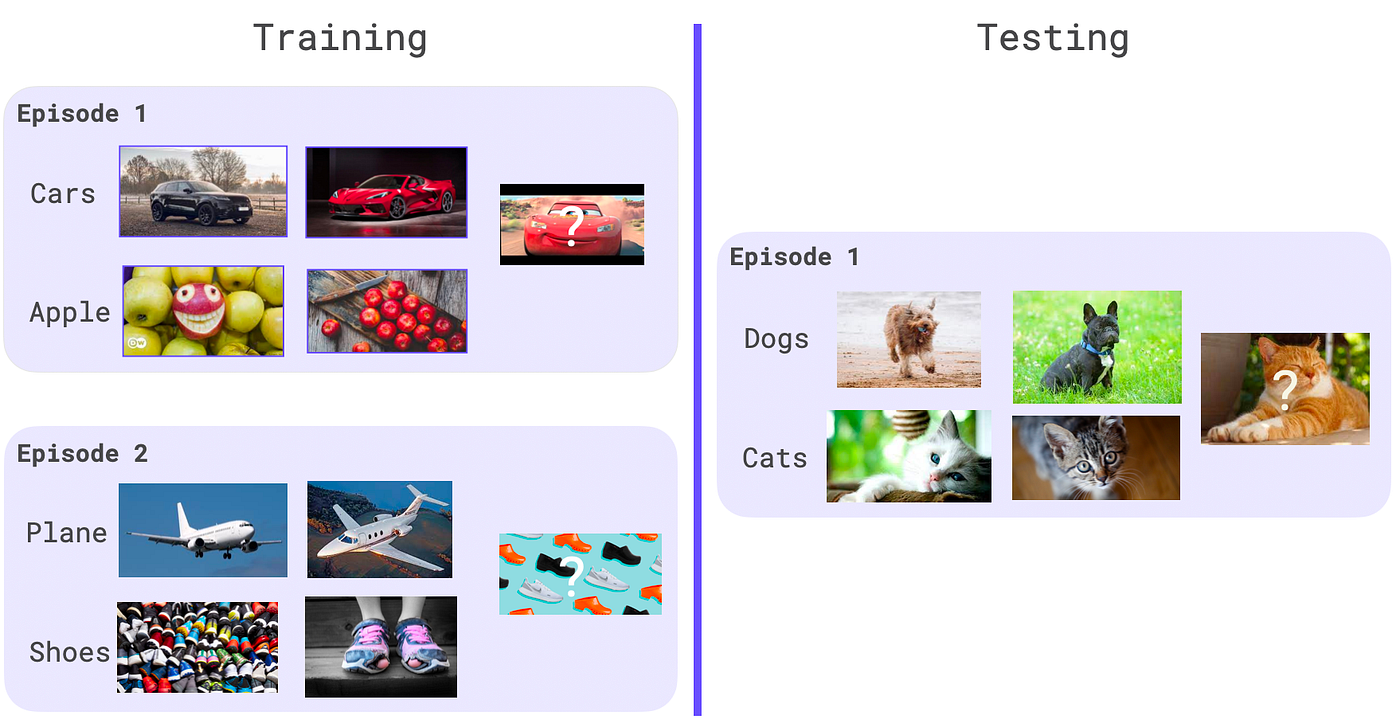
When training the model with a meta-learning algorithm, the model will average its gradients over meta_batch_size few-shot episode before performing an optimizer step. Traditionally, within a meta epoch, multiple optimizer steps are performed before model evaluation.
Here is the pseudo-code of the MetaLoop as described above.
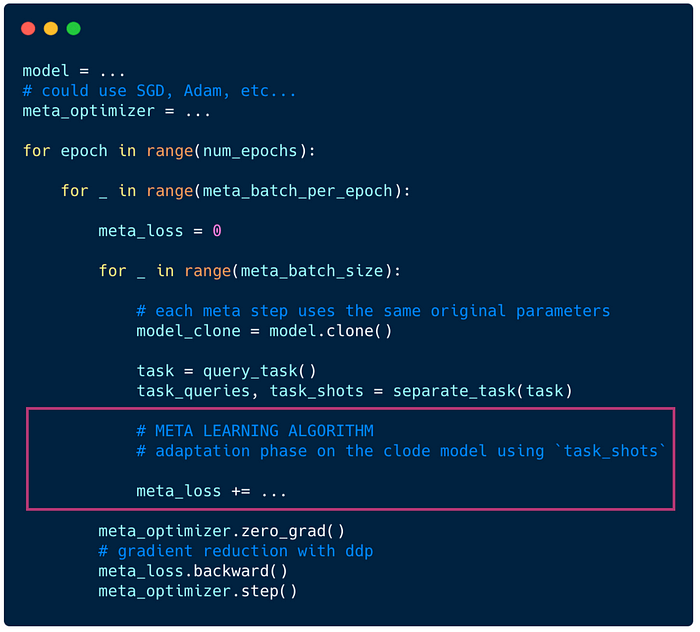
Note: The 2 following code snippets would be written within the part in purple.
The Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks paper or MAML (Chelsea Finn and al., Jul 2017) presents a way to train on multiple tasks by performing N times the computational graph of the model, where N is the number of adaptation steps.

Note: Find how differentiability with the original model parameters is maintained within Learn2Learn thanks to the model_clone and model_update methods.
However, this algorithm is quite memory intensive, it requires keeping meta_batch_size * N computational graph of the model.
A more efficient method was introduced in the Prototypical Networks for Few-shot Learning paper or prototypicalnetworks (Jake Snell and al., Jun 2017). This method is also called protonet and relies on clusters computation from the shots and softmax assign to the clusters with the queries.

The table below extracted from the Prototypical Networks paper compares the model abilities to make predictions on unseen classes with only 1 or 5examples per class on the miniImageNet dataset containing 100 classes divided into 64 training, 16 validation, and 20 test classes.
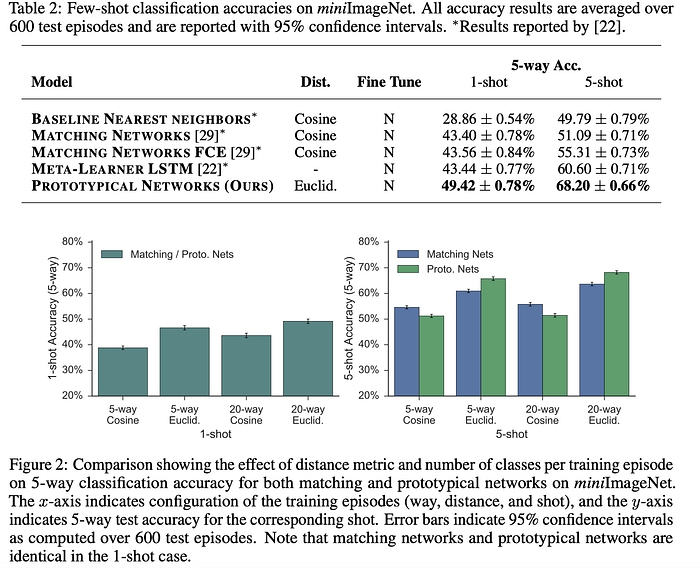
As one can observe, using the prototypicalnetworks increased the testing accuracy on never seen before data by 71 % over the nearest neighbors baseline while presented with 1 or 5examples.
To implement such methods with PyTorch Lightning, you should do 2 things:
- Implement the above logic within your LightningModule training_step and return the
meta_loss. - Set
accumulate_grad_batchesto be equal tometa_batch_size, so gradients get added across tasks.
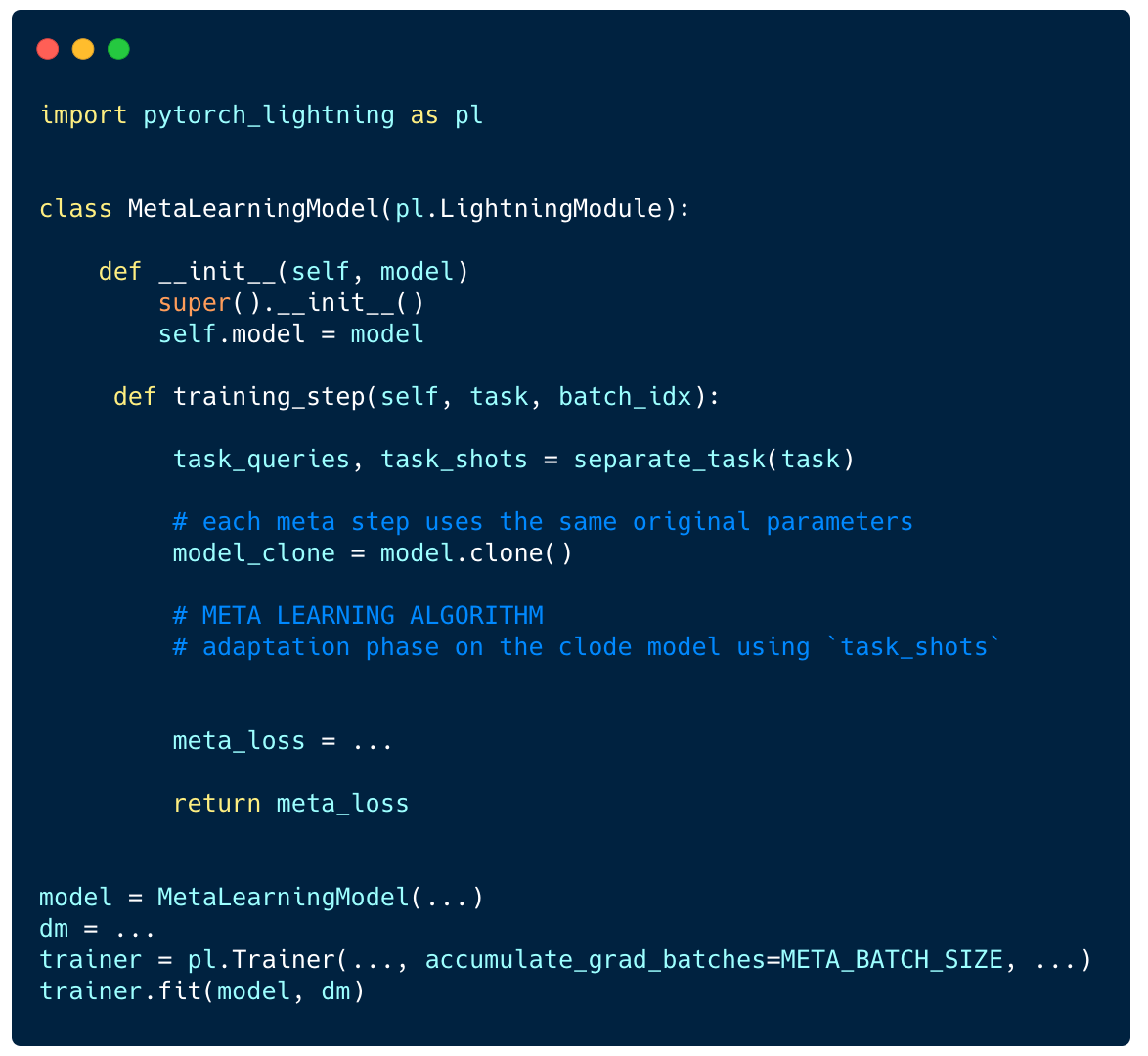
You can check their implementations: MAML or ProtoNet from learn2learn.
Furthermore, Flash adds support for ddp, find more here and there.
How to use Meta-Learning in Flash?

Install Lightning Flash
pip install lightning-flash[image]This will automatically install the latest version available for learn2learn.
Find the integration documentation there.
Flash Training Strategies
Lightning Flash 0.5.1 introduces the concept of training strategies. Training strategies are algorithms that describe how to optimize the task parameters on the provided data. The algorithms described previously are made available as training strategies for the ImageClassifer .
Find the documentation there.
- Download Data
The data should already be split by classes, so there is no overlap between train, val and test. Once done, you can easily create a DataModule using its from_tensors class method.
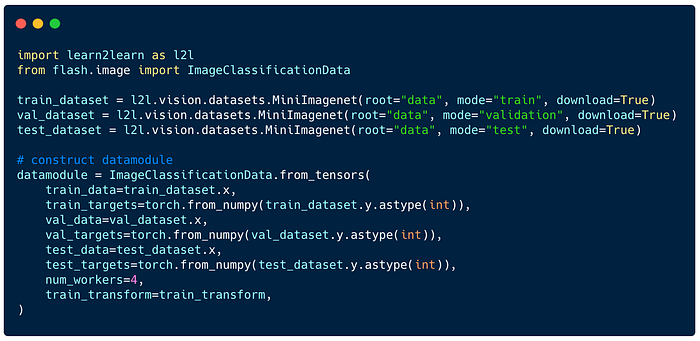
2. Initialize classifier
Create an ImageClassifier and provide training_strategy="maml" argument and the algorithm hyper-parameters through training_strategy_kwargs. Everything related to the MetaLoop can be configured right there. 🤯 Flash will take care of the rest c.f tasks sampling, accumulated gradient, distributed training, meta optimizer, etc !

3. Finetune
Finally, you need to create a Flash Trainer . To train on 2 GPUs in an optimized way, use ddp_shared accelerator and 16 bit precision.
When calling trainer.finetune , you can add a complementary freezing / freezing strategy for the model parameters. Here, we are using UnfreezeMilestones where we unfreeze the latest layers of the backbone on start, and the rest when reaching epoch 5.
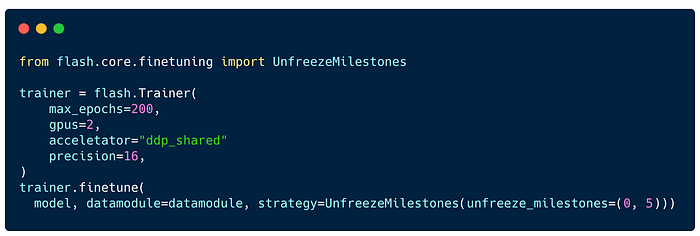
To train with Protonet the method with Flash, simply replace training_strategy="maml" by training_strategy="prototypicalnetworks".
Finally, I want to thanks the Learn2Learn Team and its creator Sébastien M. R. Arnold for their help and guidance during the integration within Lightning Flash.
Next Steps
We are currently working on some really exciting things for the future of Flash such as self-supervised learning with VISSL or Active Learning with Baal. With these integrations, Flash will provide advanced training strategies that help you to get the most out of your data.
If you’re interested in helping out with these efforts, find us on slack!
Also check out Grid.ai, which enables you to scale your Flash models without worrying about infrastructure.

Grid.AI enables you to scale training from your laptop to the cloud without having to modify a single line of code. While Grid supports all the classic Machine Learning Frameworks such as TensorFlow, Keras, PyTorch, and more. Leveraging Lightning features such as Early Stopping, Integrated Logging, Automatic Checkpointing, and CLI enables you to make the traditional MLOps behind model training seem invisible.
